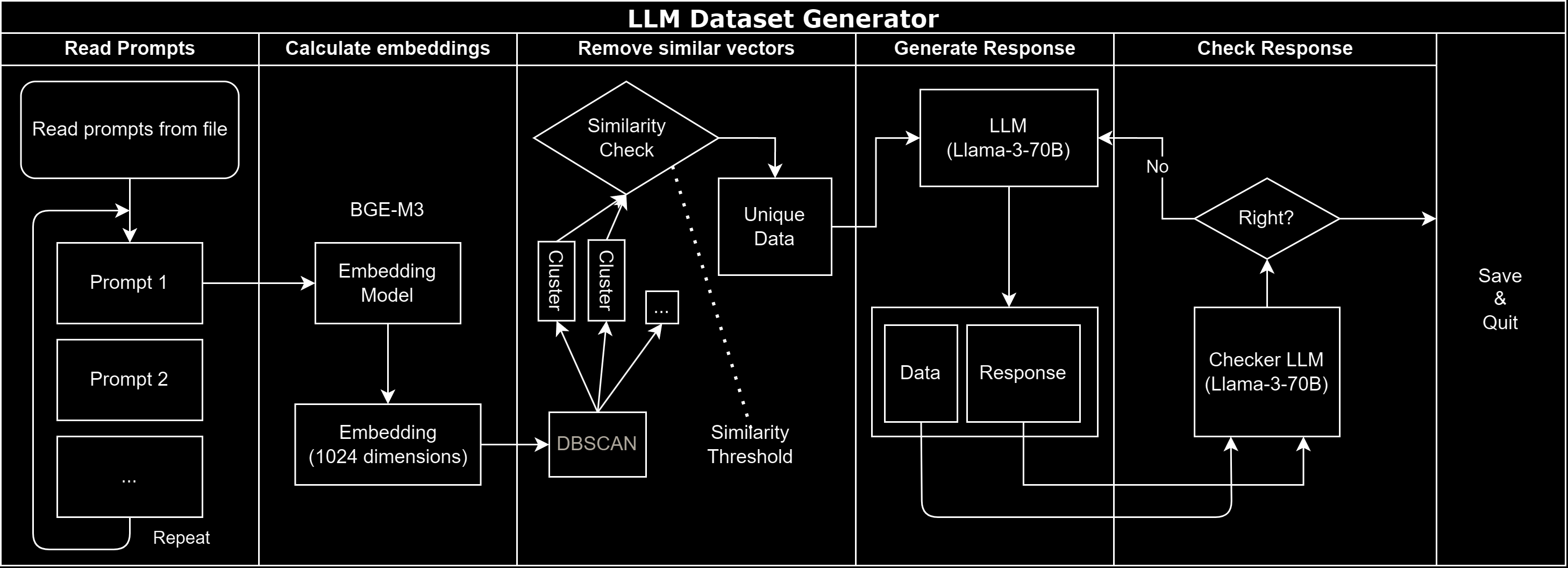
用聚类和相似度去重数据
最近在准备一个对话数据集,发现基座里面有不少相近的样本。想办法把这些相似的数据去掉啦。
首先把所有样本转换成向量表示,这一步用了BGE - M3嵌入模型。
具体的挑选可以看 这里。主要原因是 BPE - M3 是我目前唯一能找到的支持多语言(包括中文)的嵌入模型。
接着使用 DBSCAN 聚类算法把相似的样本聚合到同一簇。
对于每个簇,我计算了里面所有样本两两之间的余弦相似度。如果一个样本与其他样本的最大相似度超过设定的阈值,就把它移除掉。这样可以保证保留下来的样本之间相似度都较低。
最后把清洗过的数据存成新的文件,待后续使用。
代码方面也做了一些优化,例如异步请求、多进程处理等,让运行速度更快。同时添加了进度条和日志输出,可读性也更好了。
会作为一个数据集工具链发布哦。
Github 地址:https://github.com/Ce-daros/Collider
代码片段
- 读取输入数据并拼接 system 和 conversation:
读取数据并拼接 system 和 conversation
logging.info("Reading and concatenating data...")
all_texts = []
with open(input_file, 'r', encoding='utf-8') as f:
data = json.load(f)
logging.info(f"Loaded {len(data)} entries from {input_file}")
for entry in data:
system = entry.get("system", "")
conversation = entry.get("conversations", [])
if conversation:
value = conversation[0].get("value", "")
text = system + value
all_texts.append(text)- 计算嵌入向量:
logging.info("Calculating embeddings...")
all_embeddings = []
batch_count = 0
with torch.no_grad():
for i in tqdm(range(0, len(all_texts), batch_size), desc="Batches"):
batch = all_texts[i:i+batch_size]
# 使用模型计算嵌入向量
inputs = tokenizer(batch, padding=True, truncation=True, return_tensors="pt").to(device)
output = model(**inputs, return_dict=True)
dense_output = output.dense_output
embeddings = dense_output.cpu().numpy()
all_embeddings.append(embeddings)- DBSCAN 聚类和相似度过滤:
执行 DBSCAN 聚类
logging.info("Performing DBSCAN clustering...")
clustering = DBSCAN(eps=eps, min_samples=min_samples, metric='cosine')
cluster_labels = clustering.fit_predict(list(tqdm(all_embeddings, desc="DBSCAN input"))) # 将 tqdm 迭代器转换为列表
# 移除高相似度对
if True:
logging.info("Removing similar vectors using DBSCAN clustering and similarity threshold...")
unique_data = []
discarded_vectors = set() # 存储已舍弃的向量(字符串形式)
for label in np.unique(cluster_labels):
if label != -1:
# 对于每个簇
cluster_indices = np.where(cluster_labels == label)[0]
cluster_embeddings = all_embeddings[cluster_indices]
cluster_data = [data[i] for i in cluster_indices]
# 计算簇内相似度矩阵
similarity_matrix = cosine_similarity(cluster_embeddings)
# 根据相似度阈值选择代表
representatives = []
for i in range(len(cluster_data)):
similar_indices = np.where(similarity_matrix[i] > similarity_threshold)[0]
if len(similar_indices) == 1:
# 只有一个相似向量, 保留该向量
vector_str = str(cluster_data[i])
if vector_str not in discarded_vectors:
representatives.append(cluster_data[i])
else:
discarded_vectors.add(vector_str)
else:
# 有多个相似向量, 选择第一个作为代表
representative_index = similar_indices[0]
if i == representative_index:
vector_str = str(cluster_data[i])
if vector_str not in discarded_vectors:
representatives.append(cluster_data[i])
else:
discarded_vectors.add(str(cluster_data[i]))
unique_data.extend(representatives)
else:
# 对于噪声点直接保留
noise_indices = np.where(cluster_labels == -1)[0]
unique_data.extend([data[i] for i in noise_indices if str(data[i]) not in discarded_vectors])
logging.info(f"Saving {len(unique_data)} entries to {output_file}")
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(unique_data, f, ensure_ascii=False, indent=4)
logging.info(f"After removing: {len(unique_data)}. Before removing: {len(data)}.")
和 AI 斗智斗勇一下午(外加一整晚)…… 总算是把第一个模块写好啦。大概的数据集生成工作流是这样的: