Qwen3.5的量化与参数大小初探
大体思路
简单说就是想弄清楚:不同参数规模和量化位宽,到底对模型实际能力有多大影响?
网上能找到的 benchmark 大多是测更难的任务的,而我更需要知道的是:这个模型能不能稳定地完成如格式化输出和字符串处理这样的简单任务。
嘛,既然没有现成的,那就自己写一个吧!
这个 benchmark 在测什么
我设计了五个维度,满分 110 分:
| 维度 | 分值 | 测什么 |
|---|---|---|
| 精确性 | 30 | 单词内字母计数,字符计数、字符串反转、日期计算、小数比较、括号平衡 |
| 指令遵循 | 25 | 硬约束输出、JSON 结构化、格式限制 |
| 实用任务 | 20 | 信息抽取、spam 判断、TODO 抽取、工单路由 |
| 稳定性 | 15 | 重复一致性、长输出格式、多轮记忆 |
| 世界知识 | 20 | 常识推理、精确事实 |
代码部分
核心的评测逻辑在 eval.py 里,每个任务都有明确的预期输出,然后做精确匹配判分:
def judge_text_exact(expected: str, actual: str) -> Tuple[bool, Dict[str, Any]]:
actual_norm = normalize_text(actual)
expected_norm = normalize_text(expected)
return actual_norm == expected_norm, {
"expected": expected_norm,
"actual": actual_norm,
}没有用 LLM-as-judge,因为我没钱。
测试的模型
这次测的是 Qwen3.5 系列:
参数规模: 0.8B / 2B / 4B / 9B
量化位宽: Q3_K_M / Q4_K_M / Q5_K_M / Q6_K / Q8_0
总共 20 个组合,全部跑一遍。用的是 Llama.cpp 的 server,大家如果有并行请求 GGUF 模型的需求可以试试看。
直接看结论
跑了一小时,结果出来了!先看热力图:
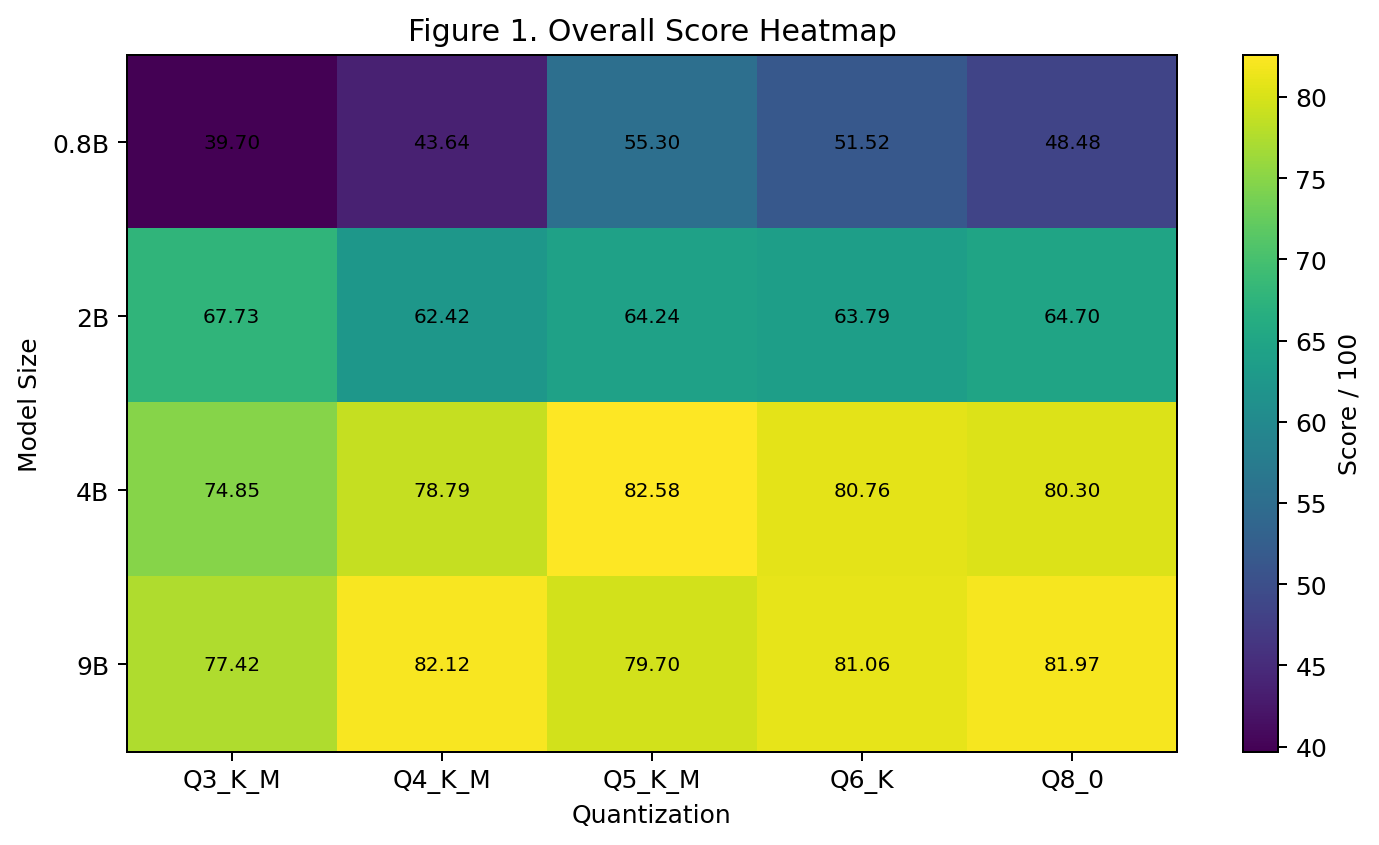
诶!看到没,第一名居然不是 9B-Q8_0,而是 4B-Q5_K_M!
几个反直觉的发现
1. 4B-Q5_K_M > 9B-Q8_0
4B 的 Q5 版本居然比 9B 的 Q8 版本总分还高。拆解一下维度看看:
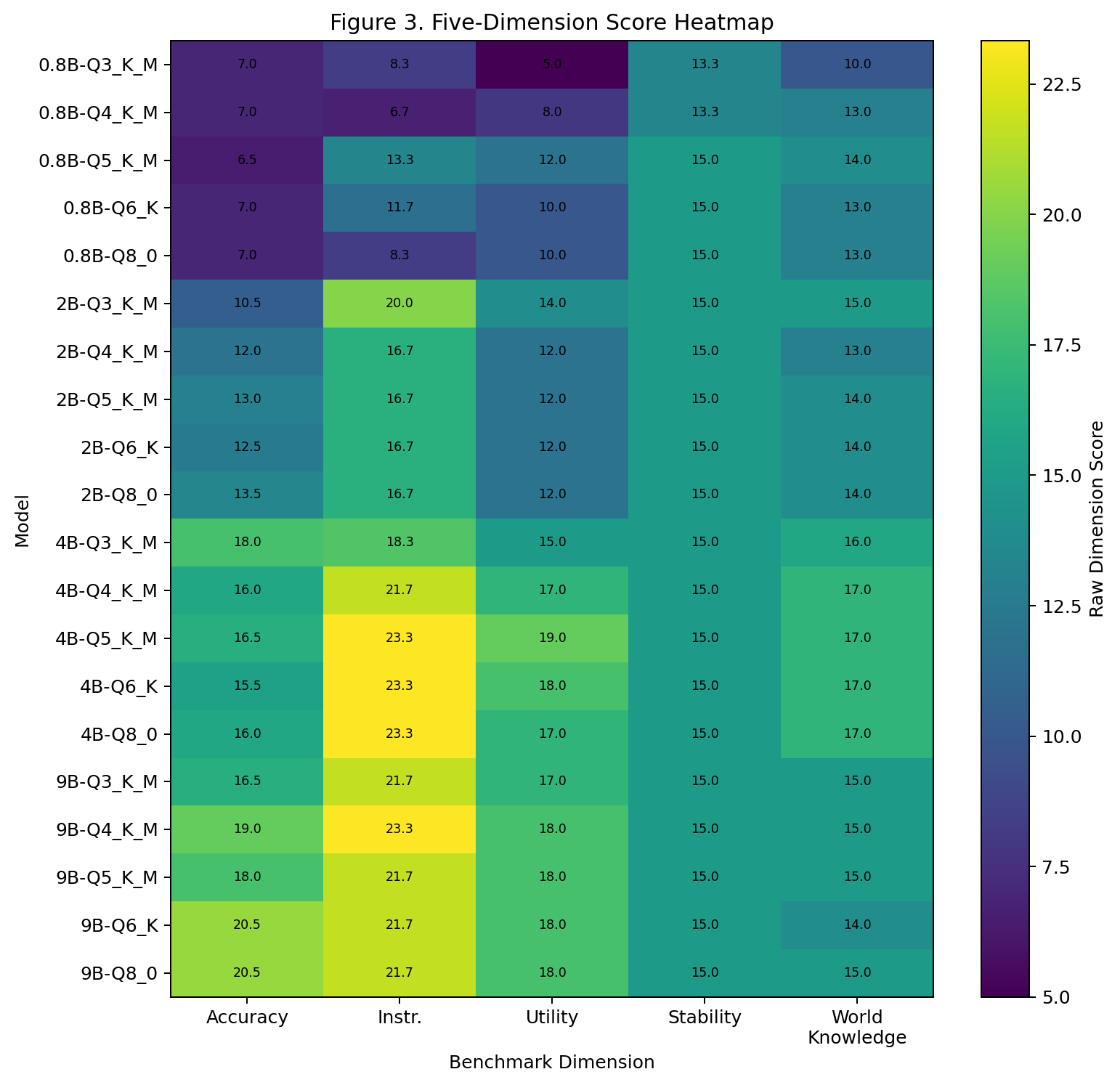
4B-Q5_K_M: 精确性 16.5 | 指令遵循 23.3 | 实用任务 19.0 | 稳定性 15.0 | 世界知识 17.0
9B-Q8_0: 精确性 20.5 | 指令遵循 21.7 | 实用任务 18.0 | 稳定性 15.0 | 世界知识 15.02. 9B-Q4_K_M > 9B-Q8_0
9B 系列里,Q4 居然比 Q8 分数高(82.12 vs 81.97)。虽然差距很小,但也很意外:
9B-Q4_K_M: 精确性 19.0 | 指令遵循 23.3 | 实用任务 18.0 | 世界知识 15.0
9B-Q8_0: 精确性 20.5 | 指令遵循 21.7 | 实用任务 18.0 | 世界知识 15.0又是指令遵循!Q4 的指令遵循能力明显更好,抵消了精确性上的劣势。
3. 0.8B-Q5 > 0.8B-Q8
0.8B 这个小模型更夸张:
0.8B-Q5_K_M: 总分 55.30 | 指令遵循 13.33
0.8B-Q8_0: 总分 48.48 | 指令遵循 8.33Q5 比 Q8 高了将近 7 分!而且指令遵循差了 5 分。不过这里需要进一步实验,究竟是偶然现象,还是量化真的能涨点,后者之前听说过类似现象。
按维度拆开看
精确性:9B 的优势在这里
| 模型 | 精确性得分 |
|---|---|
| 9B-Q8_0 | 20.5/30 |
| 9B-Q6_K | 20.5/30 |
| 9B-Q5_K_M | 18.0/30 |
| 4B-Q5_K_M | 16.5/30 |
| 2B-Q8_0 | 13.5/30 |
| 0.8B-Q8_0 | 7.0/30 |
这是唯一一个 9B 明显领先的地方。做字符串反转、日期计算这种需要精确逻辑的任务,参数量大确实有优势。但 0.8B 在这里就崩得很厉害,只有 7 分。
指令遵循:4B 意外的强
| 模型 | 指令遵循得分 |
|---|---|
| 4B-Q5_K_M | 23.33/25 |
| 4B-Q6_K | 23.33/25 |
| 4B-Q8_0 | 23.33/25 |
| 9B-Q4_K_M | 23.33/25 |
| 2B-Q3_K_M | 20.0/25 |
| 0.8B-Q5_K_M | 13.33/25 |
4B 系列在这个维度上表现特别好!Q5/Q6/Q8 都拿到了 23.33 分(满分 25)。反而是 9B 的 Q8_0 只有 21.67。
简单说就是:4B 规模可能是个甜点,刚好够学会指令遵循,又不至于过拟合到别的东西上。
世界知识:4B 居然不输 9B
| 模型 | 世界知识得分 |
|---|---|
| 4B-Q5_K_M | 17.0/20 |
| 4B-Q6_K | 17.0/20 |
| 4B-Q4_K_M | 17.0/20 |
| 4B-Q8_0 | 17.0/20 |
| 9B-Q8_0 | 15.0/20 |
| 9B-Q6_K | 14.0/20 |
诶!4B 的世界知识居然比 9B 还高?!检查了一下数据,发现主要是一些常识题(比如”小王家的大姐叫春天…”这种陷阱题)4B 答对了但 9B 答错了。
这让我怀疑:更大的模型可能更容易被表面模式误导,反而在一些需要反常识推理的题上翻车。
稳定性:大部分都很稳
稳定性这个维度,绝大部分模型都是满分 15 分。只有 0.8B 的 Q3 和 Q4 版本掉了链子(13.33 分)。
简单说就是:只要不是 0.8B 这种超小模型,量化对稳定性影响不大。
我对不同档位的建议
基于这次实验,给想本地部署的同学一点参考:
0.8B:玩具级别
总分 40-55,精确性和指令遵循都崩得厉害。只适合最简单的文本分类或者玩玩而已,别指望它做正经任务。
2B:能用但不稳
总分 62-68,比 0.8B 好很多,但精确性只有 10-13 分。做一些对准确性要求不高的任务可以,但涉及字符串处理或格式化输出时要小心。
4B:本次实验的甜点
总分 75-83,最均衡的选择。尤其是 Q5_K_M 版本,居然在总分上干掉了 9B 的所有版本!如果你要本地部署一个通用模型,4B-Q5 是我最推荐的。
9B:上限高但有坑
总分 77-82,精确性确实最强,但指令遵循有时候反而不如 4B。
这个 benchmark 的局限
说实话,这个评测也有问题,比如全部使用精确匹配判分,模型多一个”好的,答案是:”的前缀就算错。实际使用中可能没这么苛刻。没有创意写作、代码能力等测试。偏向规则和结构化任务,不代表开放生成的审美。但我觉得这个 benchmark 还是合格的。因为它几分钟就可以评判一个本地部署的模型的大概质量。
最后的结论
跑完这 20 个模型,最大的收获是:
量化不是均匀削弱能力。有的维度对量化敏感,有的不敏感。
参数规模和量化位宽不能简单互换。不是 4B-Q8 就能当 9B-Q4 用的。(笑)
4B 可能是本地部署的甜点。Qwen3 的 2507 时代已经有证明了。
谢谢看到这里的你!今天也辛苦了!